But first ... I'd like to mention that soon the ECRYPT-NET Summer School on cryptography for the cloud in Leuven is coming up.
This blog post can be seen as an intro to cryptology in the cloud; so there are some topics we will for sure hear about at the event in depth. I'm looking forward to a good discourse during the scheduled talks and to the discussions afterwards.
Part I: Requirements and security goals for the Cloud
The cloud here is loosly defined as computing and storage resources out-sourced to servers located off-site that are on-demand accessible via Internet.
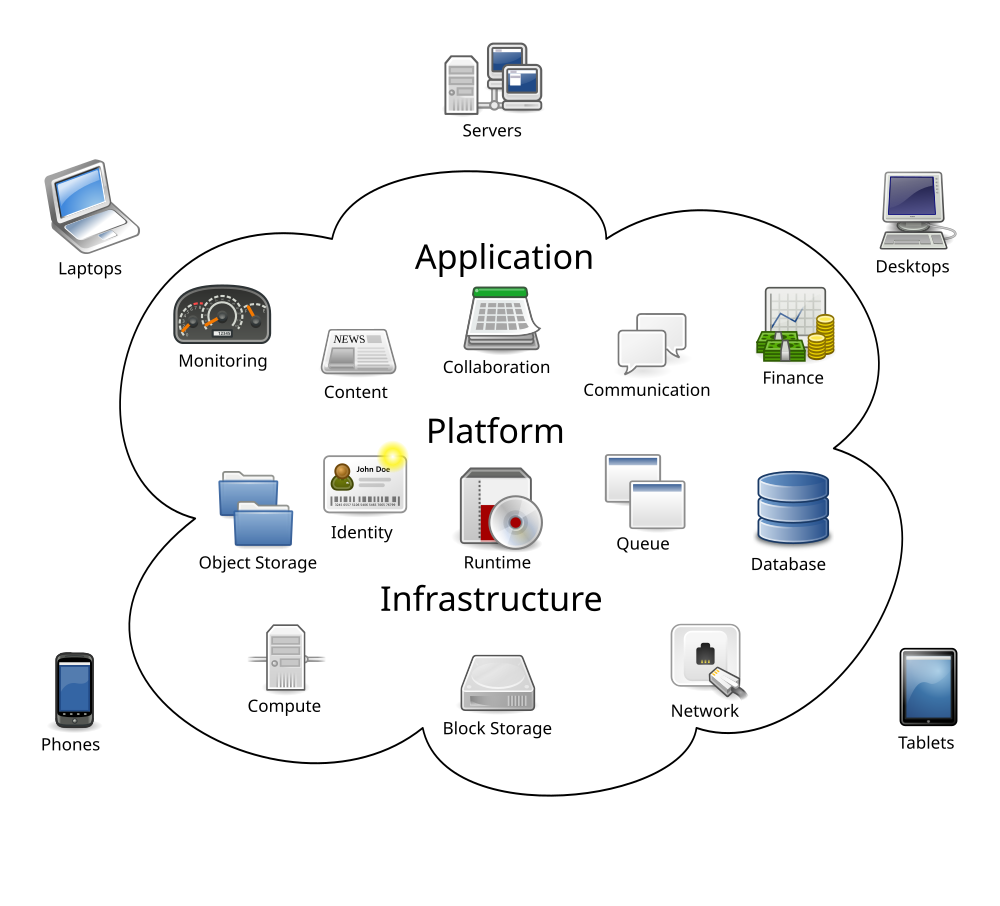 |
| Overview of cloud computing services to be secured (Image by Wikimedia user Sam Johnston) |
Requirements and the according cryptologic counter-measures are defined for various use-cases (such as depicted in the image) and briefly explained. It is important to realize that this needs to be done without deliberately weakening (or "back-dooring") solutions, as is sometimes suggested. To ensure democratic use of the developed technologies it is vital to see that the difference of a "front door" and a "back door" is merely ones viewpoint. Intentionally implementing two entrances makes an attacker happy not the legitimate user.
Transparent services, meaning the use of the cloud as if it was on-site, should ideally be built upon a back-end with verifiable, clear, possibly standardized, cryptologic concepts and open code for public scrutiny.
To capture the real-world cloud settings one has to view it from different perspectives: First the one of a private entity (user), then that of an organization (such as a company) and lastly the global perspectives of, say, a government.
An interesting starting-point for threats we have to consider, is the Cloud Security Alliance's 2016 report for cloud security naming twelve critical issues ranked by severity of real-world impact.
Data breaches is followed directly by weak identity, credential and access management and insecure Application Programming Interfaces (APIs) in this report --- issues that can be addressed by assessing requirements and tailoring cryptographic solutions from the beginning and deploying state-of-the-art implementations instead of sticking to legacy code.
Roughly four categories of requirements for the usages of the cloud can be distinguished:
- Computations in the Cloud
- Sharing Data in the Cloud
- Information Retrieval from the Cloud
- Privacy Preservation in the Cloud
The following, briefly explained, concepts tackle concrete use-cases for end-users, companies and e-Government tasks alike:
- Order-Preserving Encryption (OPE) allows efficient range queries but does it diminish security too much?
- Format-Preserving Encryption (FPE) offers in-place encryptions in legacy databases.
- Data De-Duplication (DDD) is enhancing servers' back-end performance.
- Secret Sharing Schemes (SSS) is solving back-up and availability issues by distributing encrypted parts of the whole.
- Malleable Signature Schemes (MSS) is providing flexible authentication for documents and derived data.
- Private Information Retrieval (PIR) privately accessing elements in a database.
- Provable Data Possession (PDP) ensures that the cloud is storing the (uncorrupted) files.
- Multi-Party Computation (MPC) allows secure cooperation across the Internet.
- Verifiable Computation (VC) builds trust in results of a delegated computation.
Let's hope this trend continues and ultimately leads to reliable, standardized primitives for real-world applications.
Stay tuned for Part II: Requirements and security goals for the IoT...
